
TL;DR:
- An incident response SLA is a formal agreement that clearly defines response timelines, roles, and escalation procedures for cybersecurity incidents. Proper configuration and measurement of metrics like MTTC are essential to ensure response effectiveness, compliance, and early detection. Regular audits, tailored SLAs for regulations, and separating outcome milestones improve incident management and client trust.
Understanding what is incident response SLA is one of those things many IT professionals think they have covered, until a breach happens and the gaps become visible fast. An incident response SLA, formally known as a Service Level Agreement for incident management, is the documented commitment that defines exactly how your team or provider must respond to a cybersecurity incident: the timelines, the escalation paths, and the accountabilities. Get it right and you have a measurable framework that holds everyone to a standard. Get it wrong and you have a document that creates false confidence while real incidents spiral.
Table of Contents
- Key takeaways
- What is an incident response SLA and its core components?
- Core metrics for measuring SLA performance
- Configuring SLAs in IT service workflows
- How regulations shape incident response timeframes
- Best practices for defining and evaluating SLA guarantees
- My perspective on incident response SLAs in practice
- How Makkarisecurity supports your SLA commitments
- FAQ
Key takeaways
| Point | Details |
|---|---|
| SLA definition matters | An incident response SLA is a formal commitment covering timelines, severity levels, roles, and escalation procedures. |
| Containment is the priority metric | Mean Time to Contain (MTTC) is the most critical SLA metric because it measures how quickly further harm is stopped. |
| Configuration accuracy is non-negotiable | Misaligned SLA triggers in platforms like ServiceNow produce silent breaches and unreliable adherence data. |
| Compliance drives SLA design | Regulations such as NIS2 impose reporting deadlines of 24 and 72 hours that must be built directly into your SLA architecture. |
| Layer your SLA outcomes | Separating acknowledgement, containment, and recovery into distinct SLA tiers prevents partial compliance from masquerading as full resolution. |
What is an incident response SLA and its core components?
An incident response SLA is a formal, documented commitment outlining the timeframes and procedures an organisation or third-party provider must follow when handling a cybersecurity incident. It is not a vague policy document. It is a structured agreement with specific, measurable obligations attached to each phase of the response lifecycle.
When people ask what is SLA in IT more broadly, the answer covers any service performance commitment. In the context of incident response, the scope tightens considerably. You are dealing with breach containment, forensic investigation, and regulatory notification. The stakes are categorically different from a standard helpdesk SLA.
A well-constructed incident response service level agreement typically includes the following components:
- Severity classification tiers. Incidents are categorised by impact and urgency, often on a scale from P1 (critical, business-wide impact) through to P4 (low-risk, isolated events). Each tier carries its own response timeframe.
- Roles and responsibilities. The SLA names who owns each response phase: triage lead, communications officer, forensic analyst, legal liaison. Ambiguity here is where breaches of both kinds occur.
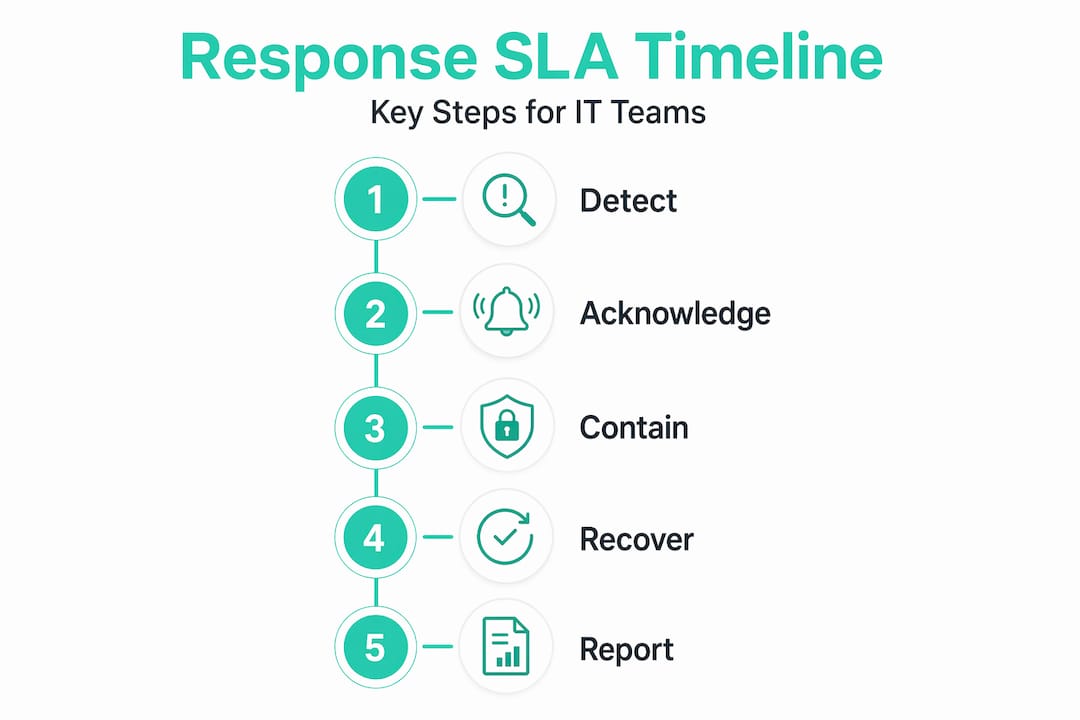
- Incident response timeframes. These specify how quickly initial acknowledgement, containment action, and full resolution must occur for each severity level. A P1 incident might demand acknowledgement within 15 minutes and containment within four hours.
- Communication and escalation protocols. Who gets notified, when, and through which channel. This includes internal escalation to senior management and external notification to regulators where required.
- Measurement and reporting obligations. How SLA performance is tracked, reported, and reviewed over time.
SLAs provide transparency and measurable targets that improve communication between IT teams and business leadership. They are not solely time targets. They include the business criteria that trigger SLA monitoring in the first place.
Core metrics for measuring SLA performance
Defining the SLA is only the first step. Measuring it accurately requires understanding the four primary incident response metrics that sit at the heart of any SLA framework.
-
Mean Time to Detect (MTTD). The average time between an incident occurring and your team becoming aware of it. A long MTTD often indicates gaps in monitoring coverage or alert fatigue.
-
Mean Time to Identify (MTTI). Once an alert fires, how long does it take to confirm the alert represents a genuine incident and classify its severity? MTTI measures the gap between detection and formal incident declaration.
-
Mean Time to Contain (MTTC). How quickly your team stops the active threat from causing further harm. Isolating a compromised host, revoking credentials, blocking a malicious IP. MTTC is often the most critical metric because it directly reflects how quickly your team limits the blast radius.
-
Mean Time to Respond or Recover (MTTR). The full resolution time from incident declaration through to restored normal operations. MTTR matters enormously for business continuity but should always be tracked separately from containment to avoid conflating two very different outcomes.
These distinct metrics separate detection, identification, containment, and recovery intervals, which allows SLA targets to be anchored to meaningful operational milestones rather than a single, blunt resolution clock.
Pro Tip: When reviewing SLA performance reports, always check whether MTTC and MTTR are reported separately. If your provider combines them into one figure, you lose the ability to see where the response actually stalled.
Configuring SLAs in IT service workflows
Understanding the theory of incident response SLAs is one thing. Getting them to work accurately inside your ticketing and IT service management (ITSM) platforms is where most organisations discover the complexity.

In platforms such as ServiceNow, SLAs are modelled as definitions with specific durations, business schedules, and lifecycle conditions that control when an SLA starts, pauses, stops, or resets. A P1 incident SLA might start the moment a ticket is created, pause when the ticket enters a "pending customer" state, and stop when it reaches "resolved." Each of those transitions must be explicitly configured.
The following table illustrates common SLA configuration parameters and their operational significance:
| Parameter | What it controls | Common misconfiguration risk |
|---|---|---|
| Start condition | When the SLA clock begins | Starts too late due to delayed ticket creation |
| Pause condition | When the clock temporarily stops | Never configured, inflating apparent response times |
| Stop condition | When the SLA is marked met or breached | Triggers at "closed" rather than "resolved", masking breaches |
| Reset condition | When the clock restarts after a change | Priority downgrade resets a P1 clock inappropriately |
| Business schedule | Working hours applied to the SLA | 24/7 SLA applied using an 8-hour business schedule |
Inconsistent SLA engine triggers or misaligned incident status changes cause silent breaches. Your dashboard shows green while actual response times are slipping. This is not a theoretical risk. It is a documented failure mode in live production environments.
Aligning SLA triggers with incident priority and severity classification is non-negotiable. When a ticket is reclassified from P2 to P1 mid-incident, your SLA engine must respond accordingly. Many organisations discover, only during a post-incident review, that their tooling never handled priority escalation correctly.
Pro Tip: Conduct a quarterly SLA audit by pulling a sample of closed P1 and P2 incidents and manually calculating response times against raw ticket timestamps. Compare those figures to your SLA dashboard. Any discrepancy tells you your configuration needs attention.
How regulations shape incident response timeframes
External regulatory requirements have become one of the most powerful forces shaping how incident response SLAs are designed. For organisations operating in the UK and Europe, the obligations are specific and legally binding.
The EU's NIS2 Directive imposes a three-stage reporting timeline for significant incidents:
| Reporting stage | Deadline | Requirement |
|---|---|---|
| Early warning | Within 24 hours of awareness | Initial notification to competent authority |
| Incident notification | Within 72 hours | Preliminary assessment including severity and impact |
| Final report | Within one month | Comprehensive analysis, root cause, and remediation steps |
These deadlines are not suggestions. Failure to meet them carries significant financial penalties and reputational consequences. Your incident response SLA must be configured to meet these statutory clocks, which means incident classification and escalation must happen rapidly enough to trigger the 24-hour notification window without delay.
GDPR and DORA impose differing notification deadlines, and regulations differ in their reporting pathways, which means a single SLA template rarely serves all compliance needs. Organisations subject to multiple frameworks require tailored SLA layers that map to each regulation's specific obligations.
There are two practical consequences for how you design your SLA:
- Incident classification must occur early enough to start the regulatory clock, not after containment is complete.
- Documentation, chain-of-custody records, and clear role assignments must be embedded in the SLA process, not treated as optional post-incident tasks.
The organisations that handle regulatory reporting cleanly are those that built compliance triggers directly into their incident response workflows from the start, not those that tried to reconstruct evidence after the fact. You can find practical guidance on this approach when reviewing enterprise security SLA frameworks in larger environments.
Best practices for defining and evaluating SLA guarantees
Crafting an incident response SLA that actually serves your organisation requires more than setting a few time targets and calling it done. The following practices distinguish teams that evaluate incident response SLA guarantees rigorously from those operating on wishful thinking.
Separate your SLA layers by outcome. Acknowledgement, containment, and recovery are three fundamentally different milestones. Distinct SLA layers prevent teams from meeting vague SLAs by resolving only partial steps. A team that acknowledges an incident within 30 minutes and then takes three days to contain it has met one SLA while failing the more consequential one.
Align SLA targets with actual risk tolerance, not aspirational benchmarks. If your organisation genuinely cannot staff a 24/7 Security Operations Centre, a four-hour P1 containment SLA is fiction. Honest SLA design accounts for real operational capabilities, which sometimes means engaging a specialist incident response retainer to fill the gaps.
Use metrics for quality, not just speed. Response time alone does not tell you whether the incident was handled correctly. Was the forensic evidence preserved with a clear chain of custody? Was the root cause identified, or was the symptom suppressed? Quality metrics matter as much as clock times when evaluating how to measure incident response SLA performance over time.
- Set formal SLA review cycles, at least quarterly for active environments.
- Use post-incident reviews to identify whether SLA targets were met for the right reasons or whether the clock was technically satisfied while the response was substantively poor.
- Automate SLA tracking within your ITSM platform to remove manual errors, but validate the automation regularly using the manual audit approach described earlier.
- Share SLA performance data with business leadership, not just the technical team. The business needs to understand what the numbers mean for risk exposure.
My perspective on incident response SLAs in practice
I have worked with organisations across the UK and Europe on live incidents, and the same pattern emerges repeatedly. Teams spend considerable effort defining response time SLAs and then fail to separate containment from recovery. They report a single "resolution time" figure that looks acceptable but masks the fact that an attacker had hours of dwell time after initial detection while containment was still being debated.
The configuration side surprises most teams when they first look closely. SLA engines in real environments behave unexpectedly when incidents get reclassified, when tickets are merged, or when business schedules are misconfigured. I have seen organisations confidently reporting 98% SLA adherence while their raw ticket data tells a completely different story. The dashboard was measuring something. It just was not measuring incident response performance.
Compliance pressure is reshaping SLA design more than any internal initiative. NIS2 and DORA have forced security managers to think about response timelines in hours rather than days. That is a good thing, even when the operational pressure is uncomfortable. The organisations that have twenty years of front-line experience behind them understand that regulatory deadlines are not the ceiling of good practice. They are the floor.
My consistent advice is this: have the honest conversation between your technical team and your business leadership about what your current SLA targets actually represent. If there is a gap between what the SLA says and what your team can genuinely deliver, close the gap rather than paper over it.
— Makkari
How Makkarisecurity supports your SLA commitments
When a breach occurs, the difference between meeting your incident response SLA and missing it often comes down to whether your response team has the tools, the experience, and the legal readiness to act immediately. Makkarisecurity delivers specialist incident response and DFIR capabilities built for exactly these moments, including live memory capture, a proprietary forensic engine, and the Eviction Pledge that guarantees threat actor removal for a minimum of 60 days.
For organisations that need court-admissible evidence and regulatory reporting support, the breach counsel and panel support service ensures chain-of-custody documentation and expert witness testimony are ready when required. Whether you need retainer support to underpin your SLA commitments or active breach response right now, Makkarisecurity operates across the UK, Gibraltar, and broader Europe with a flawless re-breach record.
FAQ
What is an incident response SLA?
An incident response SLA is a formal, documented agreement that defines the timeframes, roles, escalation procedures, and communication obligations for responding to a cybersecurity incident. It typically categorises incidents by severity and assigns specific response and containment targets to each tier.
Which incident response metric is most important for SLA measurement?
Mean Time to Contain (MTTC) is generally the most critical metric because it measures how quickly a team stops active harm. Tracking MTTC separately from full recovery time provides a clearer picture of SLA performance.
How do regulations like NIS2 affect incident response SLA design?
NIS2 requires organisations to issue an early warning within 24 hours and a fuller notification within 72 hours of becoming aware of a significant incident. These statutory deadlines must be built into SLA escalation and classification workflows, not treated as separate compliance tasks.
What causes silent SLA breaches in ITSM platforms?
Misconfigured SLA lifecycle conditions, such as incorrect pause, stop, or reset triggers, cause the SLA clock to behave inaccurately. Incidents can technically show as compliant in dashboards while actual response times have exceeded targets.
Should acknowledgement, containment, and recovery share one SLA target?
No. Separating these outcomes into distinct SLA tiers prevents partial compliance from appearing as full resolution. A team can meet an acknowledgement SLA while substantially failing on containment, which a single combined target would obscure entirely.