
TL;DR:
- Effective forensic scoping defines the boundaries, evidence collection priorities, and investigation sequence before analysis begins. It relies on established frameworks, telemetry sources, and continuous boundary adjustments to ensure a comprehensive, defensible process. Proper evidence collection order, documentation, and scope management are critical to successful post-breach remediation and legal admissibility.
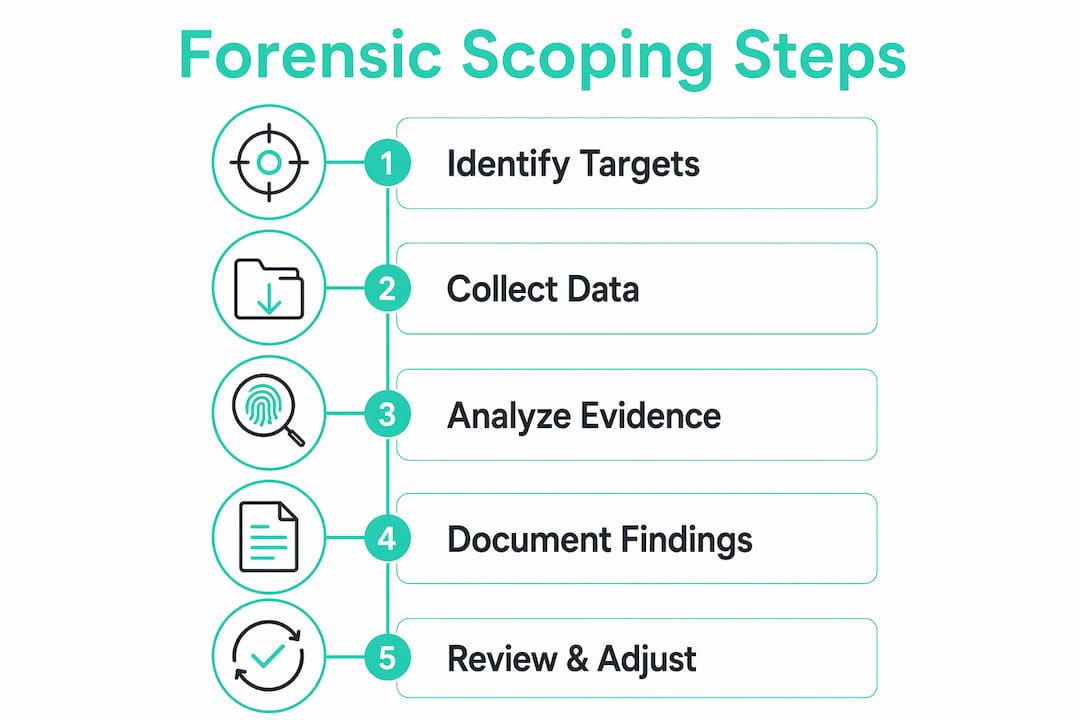
Scoping a forensic investigation after compromise is the process of defining the exact boundaries, priorities, and evidence collection sequence before deep analysis begins. Done correctly, it determines which systems, accounts, and data are in scope, what artefacts must be preserved first, and how the investigation will proceed. Frameworks including NIST SP 800-86 and RFC 3227 provide the structural foundation, while tools such as WinPmem, Windows Event Logs, and endpoint detection platforms supply the telemetry. Triage analysts review alerts, interview personnel, and produce prioritised system lists before a single disk image is taken. Getting this phase right determines whether your investigation is defensible, complete, and actionable.
What are the key elements when scoping a forensic investigation after compromise?
The scope of forensic analysis begins with a single question: what do we know, and what do we need to know? The answer shapes every subsequent decision, from which hosts to image to which logs to preserve. Forensic deliverables include an evidence summary, timeline, impact assessment, and recommendations, but none of those outputs are reliable without a well-defined scope established at the outset.
The five core elements of effective scoping are:
- Breach extent: Identify impacted systems, compromised accounts, affected data sets, and the assumed timeline of attacker activity. Without this baseline, the investigation has no boundaries.
- Order of volatility: Prioritise evidence sources by how quickly they disappear. Memory and network sessions vanish at shutdown, so volatile data must be captured before any containment action that involves rebooting or isolating a host.
- Evidence versus containment balance: Containment pressure from business stakeholders is real, but premature isolation without capture destroys artefacts. The two activities must be sequenced, not treated as competing priorities.
- Telemetry triage: Alerts from endpoint detection and response (EDR) platforms, firewall logs, and cloud audit records form the initial hypothesis. Interviews with system owners fill gaps that automated telemetry misses.
- Iterative boundary adjustment: Scope is not fixed at the start. As timeline analysis surfaces lateral movement or additional compromised accounts, the investigation boundary expands accordingly.
Pro Tip: Build a scoping hypothesis document on day one. List confirmed compromised hosts, suspected hosts, and unknown hosts in three separate columns. Update it every four hours during the active investigation phase. This single habit prevents both under-scoping and wasted effort on systems that were never touched.
The iterative, hypothesis-driven nature of forensic scoping means that your initial scope is a starting point, not a conclusion. Treat it as such from the first hour.

Which tools and data sources are essential during the scoping phase?
Effective post-compromise investigation depends on capturing the right data from the right sources in the right order. The table below maps the primary data sources to their forensic purpose and urgency.
| Data source | Forensic purpose | Urgency |
|---|---|---|
| Live memory (via WinPmem) | Captures running processes, network connections, and injected code | Critical. Capture before any reboot or isolation |
| Windows Event Logs | Authentication events, process creation, scheduled tasks, and service installation | High. Export before log rotation overwrites entries |
| EDR telemetry | Process trees, file writes, registry changes, and lateral movement indicators | High. Pull historical data immediately |
| Firewall and proxy logs | Command-and-control traffic, data exfiltration volumes, and attacker IP addresses | High. Correlate with endpoint artefacts |
| Cloud audit records (e.g., AWS CloudTrail, Azure Monitor) | API calls, privilege escalation, and storage access in cloud-hosted environments | High. Cloud logs have short default retention windows |
| Forensic disk images | Immutable copy of file system, deleted files, and persistent artefacts | Medium. Image after volatile data is secured |
Memory acquisition tools such as WinPmem produce a raw dump of RAM that preserves injected shellcode, credential material, and active network connections. These artefacts do not survive a reboot, which is why volatile evidence must be captured first in every forensic investigation process. Disk imaging with tools such as FTK Imager or dd creates a write-blocked, hash-verified copy that forms the immutable evidence record.
Chain of custody documentation maintains evidence integrity and legal defensibility, and NIST recommends standardised written procedures for every evidence handling step. This is not bureaucracy. It is the difference between findings that hold up in court and findings that get challenged on procedural grounds.
Pro Tip: For cloud environments, set log export jobs running within the first 30 minutes of an investigation. AWS CloudTrail and Azure Monitor both have configurable retention periods that may be shorter than your investigation window. Export first, analyse later.
Correlating artefacts across endpoints, network captures, and cloud audit records is what transforms individual data points into an attack path. Attack path reconstruction is the mechanism that tells you whether the adversary moved laterally from a single workstation to a domain controller, or whether the compromise was contained to one system from the start.
How to prioritise evidence collection without compromising investigation integrity
Balancing rapid containment with evidence preservation is the central tension in every cybersecurity breach recovery effort. The sequence matters more than the speed.
The RFC 3227 order of volatility provides the authoritative sequence for evidence collection:
- CPU registers and cache — captured only in specialised hardware forensics scenarios; rarely practical in enterprise IR.
- Live memory (RAM) — acquire immediately using WinPmem or a comparable tool before any network isolation or shutdown.
- Active network connections and routing tables — capture using "netstat
,arp`, and routing table exports while the host is live. - Running processes — document via process list exports and EDR telemetry before termination.
- Temporary file system and swap — export before reboot; contains fragments of recently executed code.
- Persistent storage (disk images) — image after volatile data is secured; use write blockers to prevent modification.
- Remote logging and monitoring data — pull from SIEM, EDR, and cloud platforms; these are the most durable but also the most subject to retention policy truncation.
- Physical configuration and network topology — document last; this data changes least rapidly.
"Evidence preservation constraints dictate containment actions. Volatile data loss can weaken forensic conclusions and leave the root cause permanently unknown." — Incident forensics investigative precision
Premature eradication can leave persistence mechanisms in place, and second ransomware deployments occur in approximately 10% of cases where containment precedes thorough forensic capture. That figure represents a direct operational cost of skipping the sequence. Chain of custody records must accompany every item collected, with hash values, timestamps, and handler names documented at each transfer point.
What are the common challenges in defining forensic scope during an active investigation?
Every incident response team faces the same structural obstacles when managing scope during a live investigation. Recognising them in advance reduces their impact.
- Under-scoping at the outset: Initial alerts typically surface one or two compromised hosts. Lateral movement means the true scope is almost always larger. Timeline analysis of authentication logs and EDR process trees regularly surfaces additional hosts that were not in the original scope.
- Cloud versus on-premises complexity: Cloud forensics introduces specific challenges around log availability, shared responsibility boundaries, and the absence of physical media to image. Scoping a hybrid environment requires separate evidence collection workflows for each tier.
- Stakeholder pressure to restore services: Business units push for rapid recovery. The forensic investigation process must be protected from premature closure. Documenting scope decisions and their rationale in writing creates accountability and protects the investigation from being curtailed.
- Scope creep in the opposite direction: Investigating every system in a large enterprise because "it might be affected" wastes resources and delays findings. Scope expansion must be evidence-driven, not precautionary.
- Communication gaps between IR sub-teams: Threat intelligence analysts, forensic examiners, and network defenders frequently work in parallel. Without a shared scope document updated in real time, teams duplicate effort or miss handoffs entirely.
Initial key findings and access vectors are typically available within 48 to 72 hours, with full exfiltration assessments taking one to three weeks depending on environment size and log availability. Setting these expectations with stakeholders at the start of the investigation prevents scope decisions being driven by impatience rather than evidence.
How should forensic findings drive post-compromise remediation and recovery?
Forensic findings are not just a record of what happened. They are the specification for what must be fixed, in what order, and with what verification steps.
- Root cause analysis before eradication: Root cause analysis and verified malware removal are prerequisites for remediation completeness. Removing a payload without understanding the access vector leaves the door open for reinfection through the same path. Makkarisecurity's root cause analysis methodology covers this process in detail.
- Backup integrity verification before restoration: Backup validation requires malware scans, workload consistency checks, configuration diffs, and audit log review before any production rollback. Restoring from a compromised backup reintroduces the threat. Guidance on secure backup validation outlines the layered checks required.
- Post-restoration monitoring: Confirming that no residual compromise remains requires active monitoring for at least 30 days post-restoration. Forensic timelines define the indicators of compromise (IOCs) to watch for during this period.
- Regulatory and legal reporting: Forensic timelines establish when data was first accessed or exfiltrated, which is the information regulators require under GDPR Article 33 and similar frameworks. Accurate timelines prevent both under-reporting and over-reporting.
- Hardening guided by forensic evidence: Patch and configuration changes must be driven by the specific vulnerabilities the investigation identified, not by generic hardening checklists. Generic hardening applied without forensic context frequently misses the actual attack vector.
Pro Tip: Before signing off on remediation, run a readiness assessment checklist against the restored environment. Verify that every IOC identified during the investigation has been addressed, and document the verification steps. This record protects you if the incident becomes the subject of regulatory scrutiny.
Key takeaways
Effective post-compromise forensic investigation requires scoping to be treated as a dynamic, evidence-driven process that governs both evidence collection and remediation sequencing from the first hour of response.
| Point | Details |
|---|---|
| Scope before you collect | Define impacted systems, accounts, and timeline assumptions before imaging any disk or pulling any log. |
| Follow order of volatility | Capture live memory and active network connections before any containment action that involves rebooting or isolating a host. |
| Document chain of custody | Record hash values, timestamps, and handler names at every evidence transfer point to maintain legal defensibility. |
| Treat scope as iterative | Expand investigation boundaries only when new evidence demands it; scope creep in either direction wastes time and resources. |
| Verify backups before restoring | Run malware scans, configuration diffs, and audit log reviews on backup sets before any production rollback to prevent reinfection. |
What experienced incident responders know about scoping that theory misses
The gap between a textbook scoping process and what actually works under pressure is significant. Having responded to breaches across financial services, critical infrastructure, and professional services firms, the pattern is consistent: the investigations that go wrong do so in the first four hours, not the first four days.
The most common failure is treating the initial alert as the full picture. A single compromised endpoint rarely represents the true extent of an intrusion. Threat actors who have been present for weeks have almost always moved laterally, established secondary persistence, and exfiltrated data from systems that never generated an alert. Scoping that stops at the first confirmed host is not scoping. It is wishful thinking.
The second failure is the inverse: paralysis from over-scoping. Teams that attempt to image every system in a 500-node environment before taking any containment action lose days and frequently lose the volatile evidence they were trying to protect. The answer is triage-driven scoping: confirm the blast radius using telemetry, prioritise the highest-value and most volatile evidence sources, and move with purpose.
The third failure is chain of custody treated as an afterthought. Forensic findings that cannot be verified procedurally are findings that cannot be used in legal proceedings, regulatory submissions, or insurance claims. The documentation discipline must be present from the first evidence item collected, not retrofitted at the end.
The teams that handle this well share one characteristic: they have practised it before the breach occurred. Tabletop exercises that include a scoping phase, with real tooling and real documentation workflows, produce measurably better outcomes than teams encountering the process for the first time under pressure.
— Makkari
How Makkarisecurity supports your forensic investigation scope and breach response
When an active compromise demands immediate, defensible forensic analysis, Makkarisecurity delivers the depth and speed your team needs.
Makkarisecurity's DFIR capabilities cover the full forensic investigation process: live memory capture, disk imaging, log correlation, attack path reconstruction, and court-admissible reporting. The proprietary forensic engine, built over five years, produces cross-verified results faster than standard tooling. For organisations requiring legal support, breach counsel services provide court-admissible findings with rigorous chain of custody documentation throughout. The Eviction Pledge guarantees that once a threat actor is evicted, they will not return for a minimum of 60 days or the engagement is free. Contact Makkarisecurity to scope your investigation correctly from the first hour.
FAQ
What does scoping a forensic investigation after compromise mean?
Scoping defines the boundaries, priorities, and evidence collection sequence for a post-compromise investigation before deep forensic analysis begins. It identifies which systems, accounts, and data are in scope and determines the order in which evidence must be preserved.
Why does order of volatility matter in forensic evidence collection?
Memory and active network connections disappear permanently when a host is rebooted or isolated. RFC 3227 establishes that volatile data must be captured before any containment action that disrupts the running state of a compromised system.
How long does a forensic investigation typically take after a breach?
Initial findings and access vectors are typically available within 48 to 72 hours. Full exfiltration assessments take one to three weeks, depending on environment size and the availability of logs across endpoints, network devices, and cloud platforms.
What is chain of custody and why does it matter in digital forensics?
Chain of custody is the continuous, documented record of who handled each piece of evidence, when, and how. NIST identifies standardised written procedures as the baseline requirement for maintaining evidence integrity and ensuring findings are admissible in legal or regulatory proceedings.
How do forensic findings connect to post-compromise remediation?
Forensic findings identify the root cause, access vector, and full extent of compromise, which directly specifies what must be patched, removed, or reconfigured. Remediation without forensic grounding risks missing persistence mechanisms and leaving the environment vulnerable to reinfection through the same attack path.